Lessons in scaling and “productising” an Optimisation Process or…an exercise in cloning
Lessons in scaling and “productising” an Optimisation Process or…an exercise in cloning

How does one scale themselves to avoid becoming a bottleneck?
That was the question I needed answering when, by chance, I came across the Smart Passive Income Podcast podcast episode where Dan Norris explained the origin of his company, WP Curve.
In the podcast, Dan described how he once provided a WordPress development and support service on his own. Being on his own meant he could only support a limited number of clients. **He had a desire to scale **so he could support more clients. His solution was to *productise *his services.
“Productising” involves taking a set of skills and services and turning them into a series of processes and procedures. Having these **documented **meant Dan was able to hire a team that could provide the same level of service that he once supplied on his own.
Back to my problem, which is a common one — i.e. a company resource becomes a bottleneck because there’s few/only one of them. They have a specialised skillset/knowledge and everyone regularly jokes that they wished these people could be cloned.
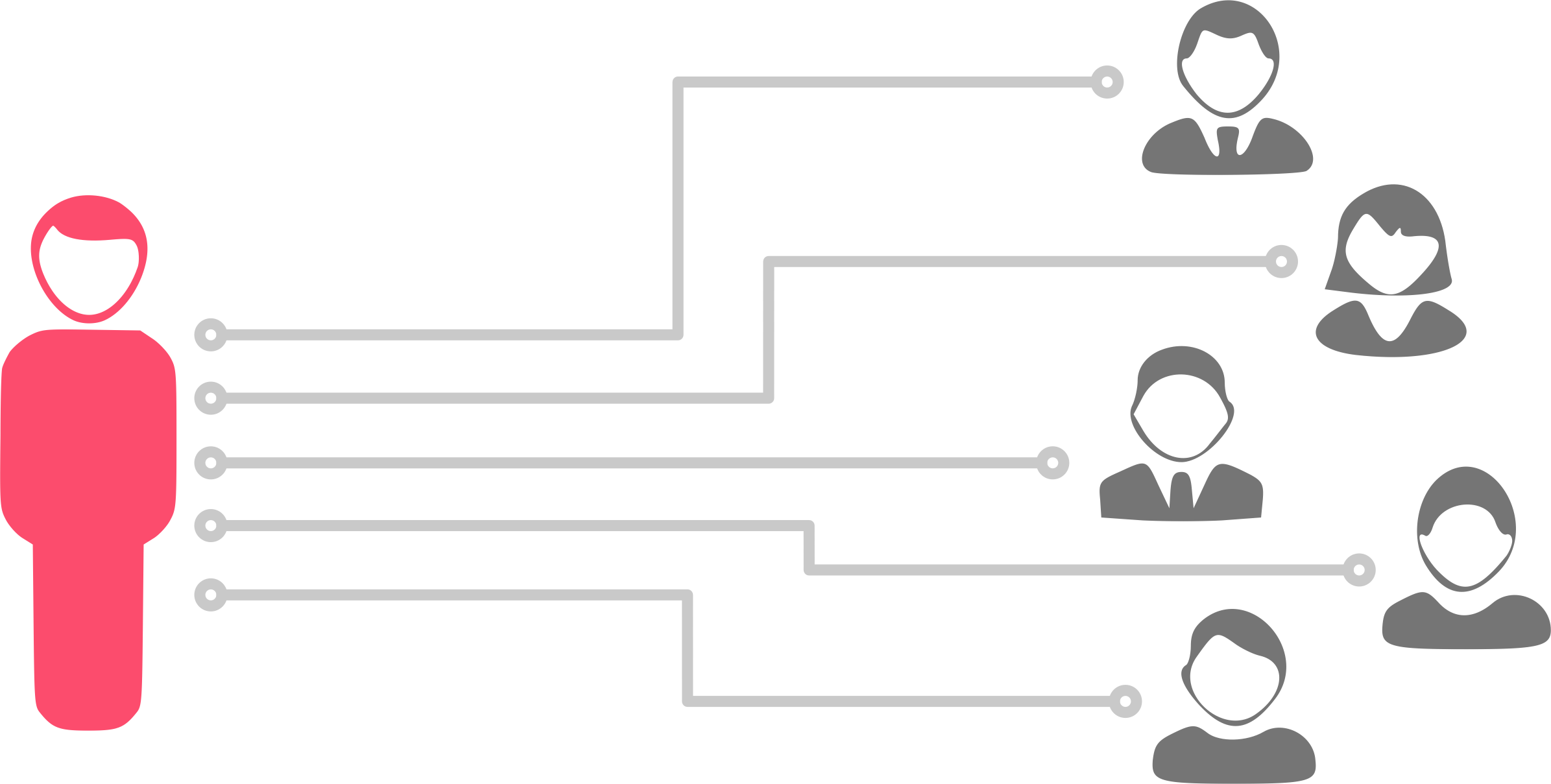 A bottleneck
A bottleneck
Specifically, I was an Optimisation Specialist tasked with rolling out and onboarding, multiple teams, to an Optimisation Process developed earlier. Each of these teams was led by a product owner, served by teams of developers, had designers on tap, and had different sets of goals to achieve.
They only had access to one optimisation specialist resource (me) and a minimal number of analysts shared across the company to help them with their experimentation efforts.
 Single optimisation specialist resource across multiple teams
Single optimisation specialist resource across multiple teams
An important advantage the company had was a product owner who was an optimisation specialist in her own right. This was hope that scaling this process could work — that it was possible to distribute specialised skills and knowledge across many people. *Alice Coburn* (the Product Owner in question) and I had developed our Optimisation Process when we both led a small team optimising the company website.
This team was successful, leading to the desire to scale the process. I’ll tell you more about this process later, for now, I want to get back to the idea of productising. You see, productising seemed to be the most effective way to roll this process out. It meant that I would, in effect, clone myself…
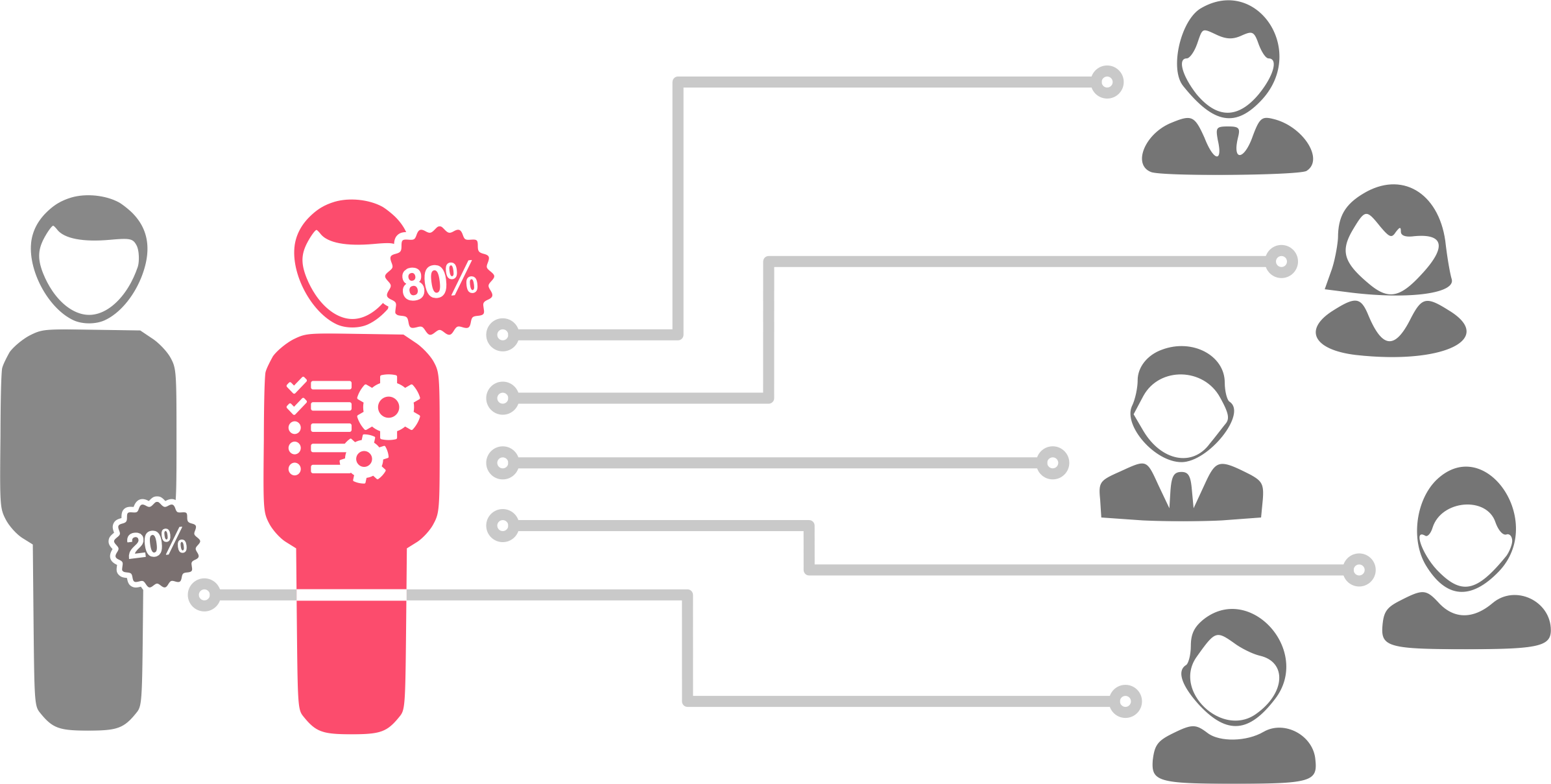 The “process me” would take over 80% of tasks
The “process me” would take over 80% of tasks
The idea is that **documentation and procedures would cover 80% of my customers’ needs. These processes and procedures would be distributed to the various members of each team, **allowing me to concentrate on the 20% of scenarios which required my personal attention. I would support all of this in a consultative capacity.
If you think this seems like I’m putting up some sort of a process shield, I’d urge you to read Reinventing Organisations, by Frederic Laloux — specifically the section around Teal Organisations. Frederic provides case studies where companies performed better when employees felt empowered to do their jobs, even if they were given additional responsibilities.
This productised service would hopefully be what empowers everyone, giving all a sense of being involved in the experimentation process.
In this article, I’ll explore how I went about the process of productising. I’ll also summarise how all of this went.
What we were trying to preserve
Here’s a high-level overview of the process we wanted to scale.
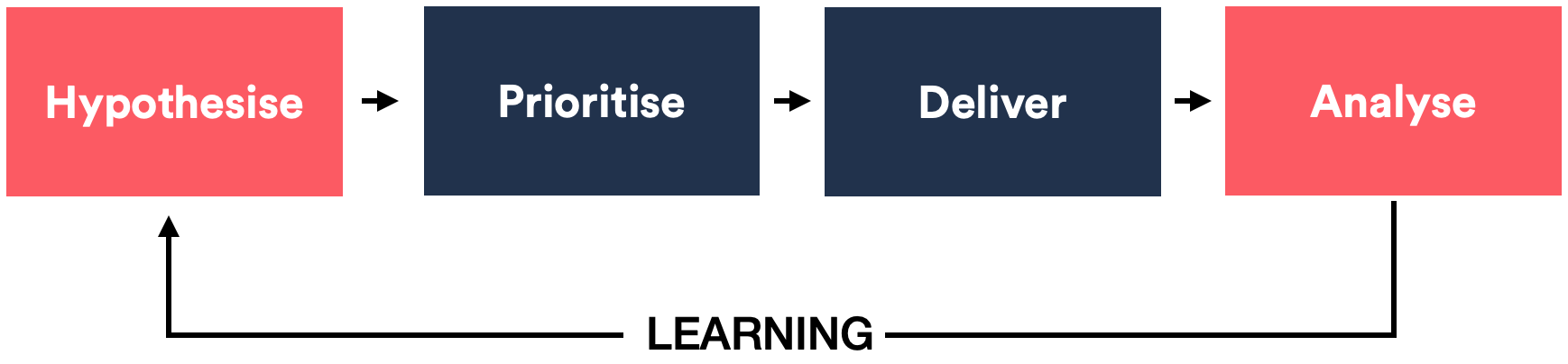
Objectivity drove this cycle of learning. There were more specific processes built into each of the core parts. All were designed with objectivity in mind (for example, using a prioritisation matrix for prioritising experiments).
When utilised in a small team, this process led to a **high output of experiments **with a **good win rate (the industry average seems to be around ~20%). **All this with minimal data validation issues. These are also metrics we would use to measure the performance of an Optimisation Specialist. So, we can use these to measure the success of our rollout.
We’re hoping these aforementioned metrics should either not be impacted or should see an improvement. In addition, we can add a few more items specifically to measure the performance of the productisation efforts:
-
Number of those experiments that were launched by people other than me
-
Adherence to the process
-
An overall reduction of my involvement in ~80% of experiments
It’s important to note that the metric I was most concerned about was the one around data validation. After all, what’s the point in increasing the volume of testing and maintaining a good win rate, if we can’t trust the data?
How difficult could it be to run some A/B tests? You just split traffic, right? Well, it can get a little tricky as it turns out. To understand why we only need to recognise the fact that optimisation testing means comparing two or more sets of data.
This means that even the most minor of issues could cause enough of a bias to deem test reads “untrustworthy”. And minor data issues are commonplace!
I’ll get to more details about how we protect data-integrity of our experiments a little later when I cover the setting up of procedures.
One last thing was a personal metric for me. It was that I will be enabled to spend time on the more complex experiments that really needed my attention. That’s the 20% of experiments that could not be catered for by strict processes.
The productisation process
Here’s an overview of the steps to take in order to productise a service…
-
Define the “customers”
-
Identify relevant tasks
-
Streamline/standardise those tasks
-
Document the processes and procedures
1. Define the “customers”
Before we can get to the core of productising, it’s important to define who the customers are for these processes — i.e. who are the individuals who would do the work? What are their roles? What are there abilities?
Knowing our customers means there’s a better chance of targeting procedures accordingly. For example, for tasks to be carried out by developers, the guides and processes would be tailored to their abilities, with documentation written in a form that makes sense for them.
 The customers: product owner, designer, analyst and developer
The customers: product owner, designer, analyst and developer
We identified our “customers” as product owners, designers, analysts and developers. I’m leaving optimisation specialist out of this list as these responsibilities will be distributed across the skillsets mentioned.
2. Identify relevant tasks
Luckily, a list of the specific tasks across the Optimisation Process already existed — Alice and I had already broken these down. We also identified tasks that needed to be broken down further. When it comes to scaling a process, every little detail matters.
Once we had this list it was easy to identify the required skill set needed for each task, as well as who would be responsible.
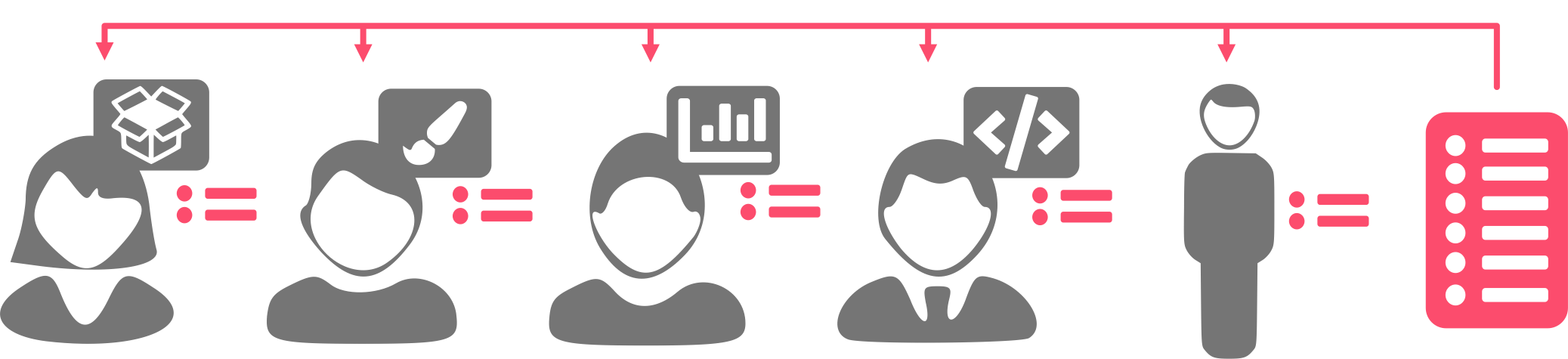 Distribution of tasks according to ability/responsibility
Distribution of tasks according to ability/responsibility
It’s important to note that I’m included as a resource at this step because some of these tasks required an optimisation specialist.
Now, when it comes to the next steps, I know my customers and the tasks I wanted them to do.
3. Streamline/standardise tasks
As you can see in the diagram below, Optimisation Specialist responsibilities needed to be distributed across multiple people (or “customers”). Therefore it is important to be aware of these so the various abilities and skillsets can be taken into account.
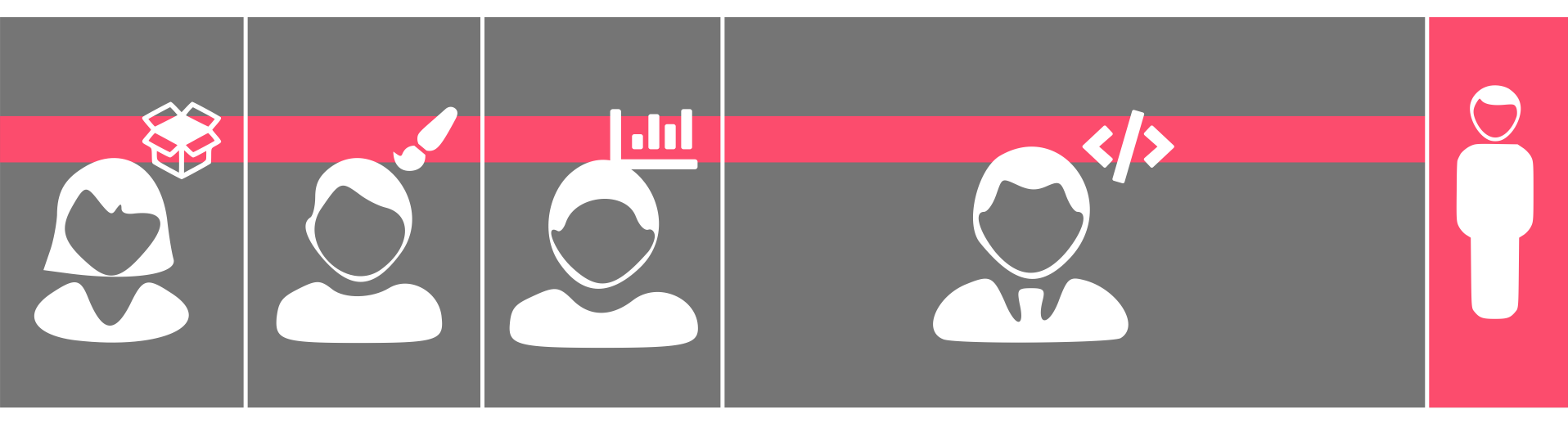 Distribution of responsibilities from the optimisation specialist
Distribution of responsibilities from the optimisation specialist
In order to facilitate this distribution and to ensure the smooth running of our experimentation programs across the company, it was important to** standardise and streamline the tasks** we had identified earlier.
We’ve all heard of the saying: “there are many ways to skin a cat”. It’s a horrible saying, I know and for the curious of you out there, I’ll save you a google and tell you that the origins seem to be from an 1840 short story called The Money Diggers by the humourist Seba Smith.
That said, with productisation, “many ways of doing the same thing” causes problems. After all, it’s much easier to support people and debug problems if everyone was following the same methodology*.* It also makes it easier to document, enabling the later inclusion of any “gotcha” scenarios and edge cases.
This standardisation and streamline of processes is a major part of the productising. So, it might make sense to illustrate these with some examples.
Here’s one such example…
 Counting traffic: Correct/Incorrect counting
Counting traffic: Correct/Incorrect counting
There are multiple ways of counting users into an experiment, ranging from the implicit (allowing the experimentation tool to do the work) to the explicit (having some custom functionality/methodology to do the work). When it comes to the explicit, there are multiple ways of implementing and integrating explicit “counting” functionality.
If we counted users into experiments using the same analyst-verified approach, this not only makes experiment build reviews faster and easier but debugging when things go wrong also becomes simpler.
By the way, if you want to find out more about why it might be important to be explicit in how you count users into experiments, you can read a previous article on this subject here.
With regards to “counting traffic” we can put procedures in place to distribute the “responsibility of counting accurately” across multiple people, giving each a responsibility and task tailored to their ability to do them.
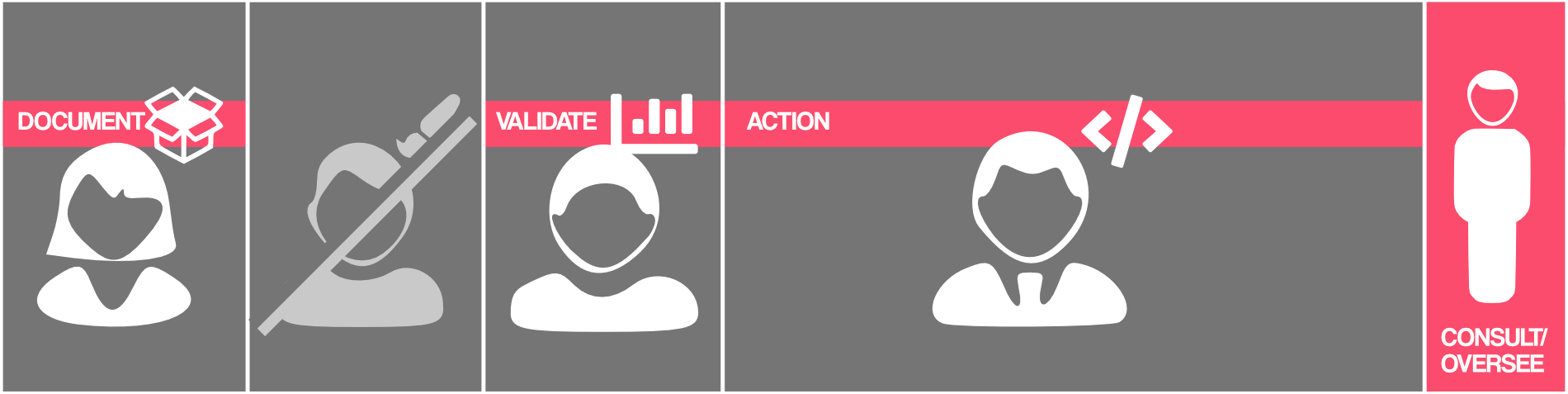 Responsibility for counting split across the users
Responsibility for counting split across the users
In our case, this would take the form of procedures designed to:
-
ensure that counting requirements are documented accurately by the product owner, in JIRA tickets
-
ensure that an analyst is aware and happy with the counting criteria
-
ensure a set of processes enabling a developer to implement the counting criteria quickly and accurately, with safeguards to give them confidence
It seems like a lot of work, but each of these steps is relatively small. They are also tasks that are standardised to ensure that the people doing the work are capable to do them. They are streamlined, to ensure they are as efficient as possible.
Another example is the process for identifying issues after launching of an experiment. These issues could be anything from problems with the setup; defects in the codebase; or simply an experiment idea which has a massive negative impact.
It’s better to catch these issues as early as possible. These are tasks normally reserved for an analyst or optimisation specialist. It involves analytics know-how as well as some stats knowledge (to recognise if what is being seen is statistically significant).
We’ve already established that analyst and optimisation specialist resource is scarce and the volume of experiments that will be launched day-to-day across the organisation will be potentially vast.
So, what do we do? Well, a benefit of standardising and streamlining tasks is that you can have a process which is easy to follow by non-specialists. This means that product owners, designers and developers can help monitor tests using the provided guide.
 The task for monitoring a test for early indications of issues
The task for monitoring a test for early indications of issues
They would obviously have support but they would be leading the checks and would be empowered with the ability to identify potentially major issues early in the experiment lifecycle.
With other parts of the process like hypothesising, it was okay to have an amount of flexibility for teams. Even so, it was important to have a “recommended” approach which ensures objectivity in the ideation process.
So, while some processes are strict, others are a little more relaxed but with recommended approaches evangelised by proponents of these approaches.
4. Document the processes and procedures
The final step in productising the Optimisation Process was simply to document it. And for this, choosing the right form of documentation was important.
Here are the many forms that documentation could take:
-
Detailed written guides
-
Tabularised procedures/checklists
-
Powerpoint slides
-
Video guides

And here are the many guises that support could take
-
Slack channel
-
Knowledge sharing sessions
-
Office hours
It’s not realistic to provide all of the different levels of documentation for every single process, but it helps.
Some tasks like the procedures to build an experiment campaign needed these multiple levels of documentation — it’s **that **important! So, I found that I started with a detailed guide along with classroom-like knowledge sharing sessions, but quickly ended up needed to create video guides (reading documentation caused friction for some).
These video guides were also detailed and sometimes developers just needed a refresher, so a brief summary was created along with a checklist to validate that experiments had been built correctly.
As mentioned previously, JIRA tickets set the tone for all the processes that were to be followed. So it was important that each experiment ticket had all the relevant information for later procedures to be followed effectively.
There were templates and guides for product owners and business analysts to write tickets. This included information like defining the counting location and properly formatted hypotheses, etc.
All of this took a while, and there were various iterations required on the documentation to get it right. Whenever I came across situations that weren’t covered by existing processes or documentation, I’d make sure these were added so I wouldn’t need to deal with them personally again.
All of this was supported by a slack channel for support and regular office hours for one-to-one support, along with group sessions when needed.
How did it all go?
It wasn’t easy to defer people who want your time to a set of documented processes instead. Common responses were: “I need to get this done now. I don’t have time to read the documentation” and “Can’t you just do it this time? I’ll read it for the next experiment”. There were some questions asked about why a standardised process was needed: after all “there are many ways to skin a cat” (thanks Seba).
In the beginning, I sometimes took groups of individuals through the set of tasks, referring to the documentation as we went. Eventually, these became fewer and fewer cases. The video guides really helped in this regard. I found I was instead presented with completed experiments to review.
I was surprised to find that some eagerly consumed every article and process I documented, even going as far as evangelising the documentation to spread the knowledge wider across the company. These same individuals built up enough knowledge and no-how to be able to support others.
New documents needed to be created constantly, and stale ones had to be deprecated and this was hard to start with but got easier once I got used to the documentation process itself.
There were instances where teams identified defects with their launched experiments on their own without an analyst or optimisation specialist.
Just to reiterate, my goal was not to hand over all responsibilities of an optimisation specialist to these processes, instead, they were meant to cover 80% of user cases. The other 20% still requiring my personal attention and that’s exactly what I found happening.
In the end, these “optimisation specialist” tasks were not a bottleneck and allowed the company to scale up the volume of tests launched. I don’t think I can share the data, all I can say is that there was a big increase.
*What about win rates? *Well, they were low at first but over a relatively short period of time, they did settle to a range we were happy with.
And data integrity? In the beginning, a larger proportion of tests needed to be restarted. This soon reduced with further iterations of the documentation and procedures. The office hours helped those who wanted to improve their skills and I found that I relied on some of these individuals more and more for support.
Of course, there’s always more that could be done. Automation, for example. But the groundwork was set for future innovations in this area.
All in all, it was an interesting and successful experiment. Don’t get me wrong, I would much prefer to have more specialised resources to build something like the Experimentation Council that Google has. This way, there’d be no need to distribute tasks across other skillsets (despite how keen some were to accept them).
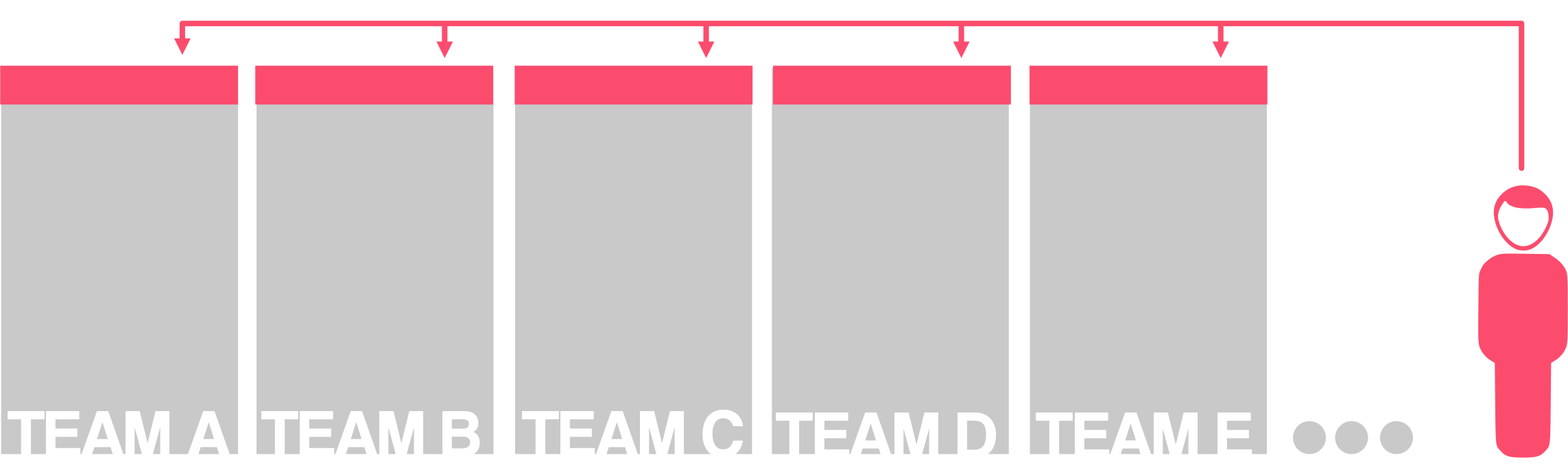
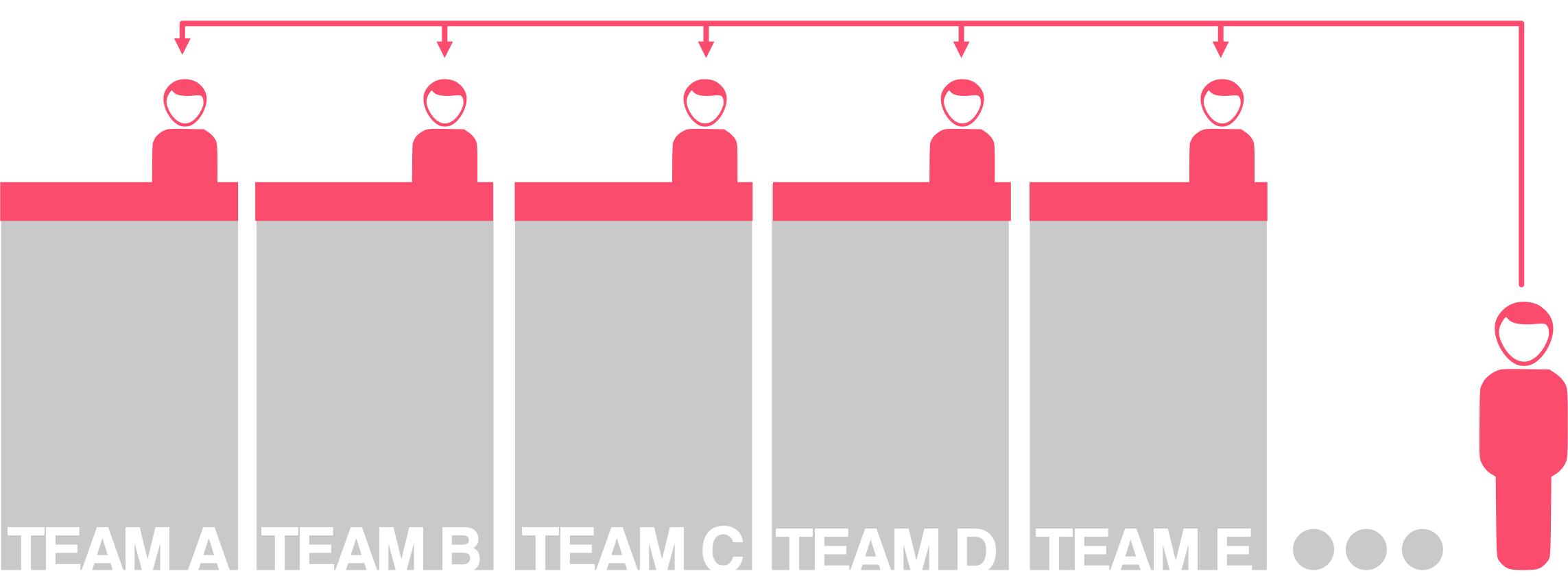 One optimisation specialist resource shared across many teams
One optimisation specialist resource shared across many teams
But even if I did have access to more resources, there’s still a huge advantage to productising the service. These streamlined and standardised tasks will help these resources support their “customers” with greater ease and efficiency.
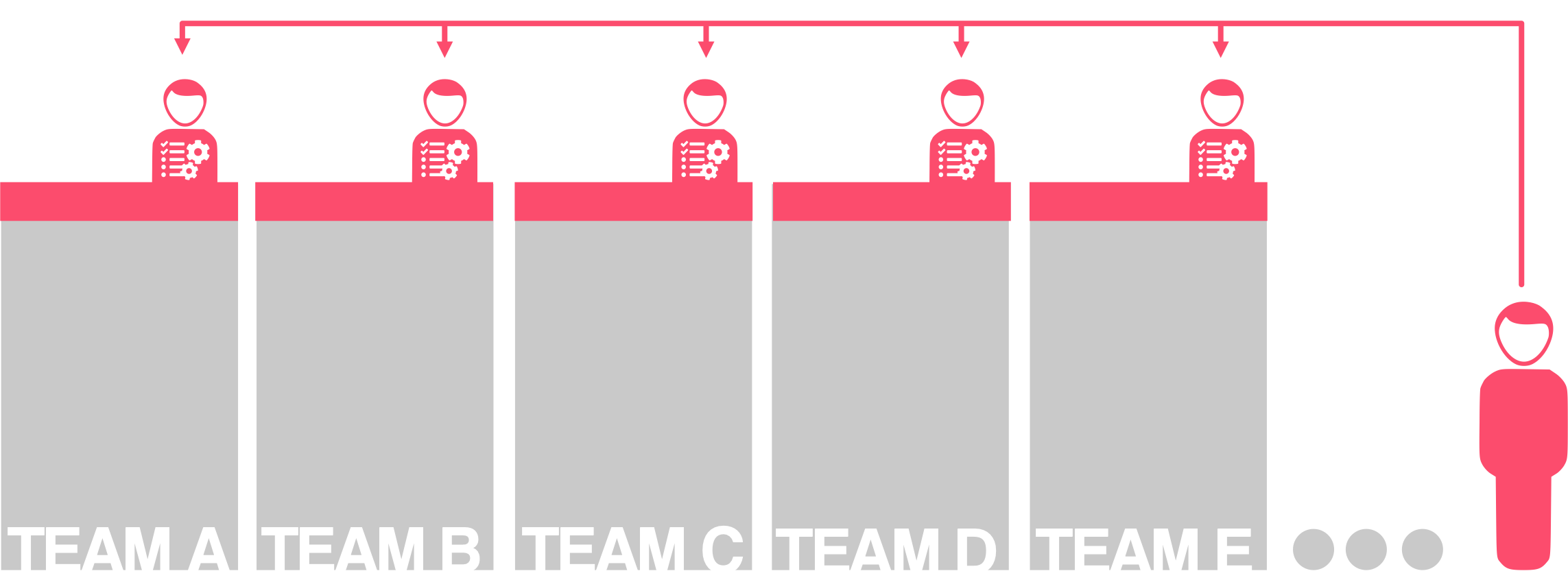 Optimisation Specialist teams bolstered by procedures
Optimisation Specialist teams bolstered by procedures
There were many with whom I relied on for support. These include the aforementioned Alice Coburn, who helped define some of the processes with me; Ian Randolph who taught and evangelised the Teal Organisation methods that underpin this approach; and Jon Moore, who supported this whole exercise at an organisational level, as well as suggesting things like producing videos to share knowledge.
I’d be interested to hear thoughts from many of you out there. I know many others struggle with the same issues of being a bottleneck in the experimentation process.
Hope this helps you all! Happy experimenting!